Snowplow

Snowplow é uma companhia com sede em Londres que oferece uma “Behavioral Data Platform” na nuvem e também uma versão open source. Segundo o site oficial, eles são a terceira ferramenta de web tracking mais usada, atrás do Google Analytics e Facebook.
Motivação para este post
O processo de instalação e configuração do Snowplow Open Source na Google Cloud é bastante complexo e, para piorar, a documentação está muito desatualizada.
A documentação também é open-source e eu cheguei a enviar pull requests corrigindo alguns dos
erros que encontrei.
De qualquer forma, documentei tudo neste artigo para referência futura.
Espero que ajude alguém também.
Eu fiz o processo todo entre dezembro de 2022 e janeiro de 2023 usando um MacBook Pro M1. Para meu uso específico, ativei tanto BigQuery quando PostgreSQL, o que custa cerca de $240 por mês.
Normalmente usa-se apenas um Data Warehouse. Na GCP eu recomendo o BigQuery, pois:
- Lida bem com grandes volumes de dados
- Alguns pacotes do dbt, como o snowplow_ecommerce não são compatíveis com PostgreSQL ainda.
- Pode custar menos, dependendo do uso (mesmo com Pub/Sub a mais)
- O BigQuery é cobrado por uso e não por tempo online.
- O primeiro terabyte de armazenagem é gratuito.
Visão geral
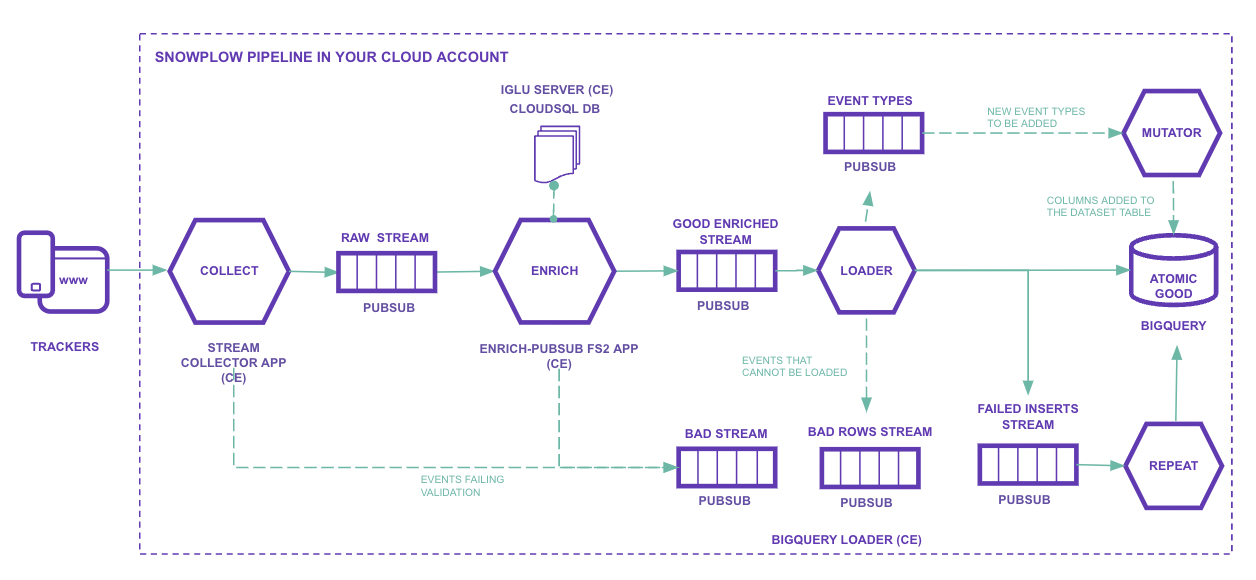
Explicando a imagem item-a-item:
Trackers: É de onde queremos coletar informações.
É possível rastrear qualquer coisa capaz de fazer chamadas REST, como websites, aplicativos mobile e bancos de dados.
As SDKs ajudam bastante nesse processo.
Os dados são enviados seguindo um schema explícito que você mesmo define.Iglu Server: Cloud Engine (com load balancer) e banco Cloud SQL.
É um repositório de schemas.
Eles são definidos em arquivos JSON Schema e podem ser versionados, por exemplo: YouTube JSON Schema e GA Ecommerce Schema.Stream collector app: Compute Engine (com load balancer).
Contém o endpoint HTTP que recebe eventos raw, os serializa e os envia para tópicos do Pub/Sub (sp-raw-topicousp-bad-1-topic).Se o evento for muito grande, por exemplo, ele é enviado para o tópico PubSub de bad data.
Enrich PubSub: Aplicação JVM no Compute Engine (uma ou mais VMs).
Nesta etapa, eventos do Raw Stream (sp-raw-topic, escritos pelo collector) são lidos e validados.- Se o evento não corresponder a um schema definido no Iglu Server, esse evento é enviado para o
Bad Stream.
Isso previne dados falsos ou de má qualidade irem para produção e também permite analisar o schema recebido, o que ajuda a encontrar possíveis erros.
No Google Analytics esses dados seriam simplesmente ignorados. - Se o evento corresponder a um schema, ele será “enriquecido” de acordo com o que você
configurou.
Por exemplo:- Separar o User Agent em partes:
- Tipo de dispositivo
- Sistema operacional
- Versão do sistema
- etc.
- Anonimizar IPs
- Filtrar dados pessoais (PII)
- Extender informações de geolocalização
- Separar o User Agent em partes:
Existem vários enrichments disponíveis.
Após “enriquecido”, o evento é enviado ao tópico Good Enriched (
sp-enriched-topic).- Se o evento não corresponder a um schema definido no Iglu Server, esse evento é enviado para o
Bad Stream.
Loader: carrega nas tabelas
Se o loader não estiver conseguindo inserir as linhas no BigQuery, elas são enviadas para um stream de failed inserts e a insersão é tentada novamente.Mutator: É usado quando algum schema precisar ser alterado ou extendido. Todos os eventos vão para uma mesma tabela gigante. Alterar um schema pode causar um grande problema.
Terraform
Em vez de criar e configurar cada recurso manualmente pela interface do Google Cloud ou pela linha de comando, com Terraform você define, de forma declarativa, a infraestrutura como código em uma linguagem própria baseada na HCL (HashiCorp Configuration Language).
Como qualquer código, os arquivos do Terraform podem ser versionados, o que facilita realizar modificações e rollbacks.
Existe um Quick Start que realiza o deploy utilizando Terraform. Infelizmente os módulos atuais não cobrem todos os setups e alguns deles estão bem desatualizados. Ainda assim eu os usarei como base, pois o Terraform reduz o risco de erros e facilita manter a infraestrutura.
Pré-requisitos
Criação de um projeto
Crie um projeto na Google Cloud e ative billing.
Usarei o nomeprojeto-snowplowneste artigo.Instalação do Terraform
brew install terraformInstalação da Google Cloud CLI
brew install google-cloud-sdk$ gcloud version Google Cloud SDK 412.0.0 bq 2.0.83 core 2022.12.09 gcloud-crc32c 1.0.0 gsutil 5.17gcloud auth loginAdicione no
~/.zshrc:source "$(brew --prefix)/Caskroom/google-cloud-sdk/latest/google-cloud-sdk/path.zsh.incEsse comando irá adicionar o diretório
/opt/homebrew/Caskroom/google-cloud-sdk/latest/google-cloud-sdk/binao PATH.Service account
Crie uma service account chamada
spsetupMenu » IAM and admin » Service accounts » Create Service AccountCrie uma chave
KEYS » Add Key » Key type: JSON
Salve o arquivo como~/Snowplow/key.jsonAponte a variável de ambiente para o caminho do arquivo
export GOOGLE_APPLICATION_CREDENTIALS="/Users/julio/Snowplow/key.json"
Ativação das APIs
Entre em cada um dos links abaixo e ative as APIs.
VPC e Subnets
A configuração “segura” do Snowplow requer uma VPC. Ela pode ser criada pela interface web, linha de comando ou Terraform.
Pela linha de comando:
gcloud compute networks create \ vpc-snowplow \ --project=projeto-snowplow \ --description=Snowplow\ VPC \ --subnet-mode=custom \ --mtu=1460 \ --bgp-routing-mode=regionalgcloud compute networks subnets create \ vpc-snowplow-europe-west3 \ --project=projeto-snowplow \ --range=10.0.0.0/24 \ --stack-type=IPV4_ONLY \ --network=vpc-snowplow \ --region=europe-west3 \ --enable-private-ip-google-accessPelo Terraform:
# VPC # https://www.terraform.io/docs/providers/google/r/compute_network.html # Keep the default route (0.0.0.0/0) to allow internet access resource "google_compute_network" "snowplow_vpc" { name = "snowplow-vpc" routing_mode = "REGIONAL" auto_create_subnetworks = false delete_default_routes_on_create = false }# Private Subnet # https://www.terraform.io/docs/providers/google/r/compute_subnetwork.html resource "google_compute_subnetwork" "snowplow_private_subnet" { name = "snowplow-private-subnet-europe-west3" ip_cidr_range = "10.0.0.0/24" region = var.region network = google_compute_network.snowplow_vpc.id private_ip_google_access = true }
Cloud Router
Pela linha de comando:
gcloud compute routers create router-snowplow \ --project=projeto-snowplow \ --description=To\ allow\ access\ to\ the\ internet \ --region=europe-west3 \ --network=vpc-snowplow \ --set-advertisement-mode=customPelo Terraform:
# Cloud Router # https://www.terraform.io/docs/providers/google/r/compute_router.html resource "google_compute_router" "snowplow_router" { name = "snowplow-router" region = var.region network = google_compute_network.snowplow_vpc.id bgp { asn = 64514 advertise_mode = "CUSTOM" } }
Cloud NAT
Crie um NAT gateway. É por ele que as VMs terão acesso à internet.
Pelo Terraform:
# NAT Gateway # https://www.terraform.io/docs/providers/google/r/compute_router_nat.html resource "google_compute_router_nat" "snowplow_nat" { name = "snowplow-nat" router = google_compute_router.snowplow_router.name region = google_compute_router.snowplow_router.region nat_ip_allocate_option = "AUTO_ONLY" source_subnetwork_ip_ranges_to_nat = "LIST_OF_SUBNETWORKS" subnetwork { name = google_compute_subnetwork.snowplow_private_subnet.id source_ip_ranges_to_nat = ["ALL_IP_RANGES"] } log_config { enable = true filter = "ERRORS_ONLY" } }
Java
brew install java brew install openjdksudo ln -sfn \ $(brew --prefix)/opt/openjdk@11/libexec/openjdk.jdk \ /Library/Java/JavaVirtualMachines/openjdk-11.jdkIgluctl
Copie o link da última versão disponível em https://github.com/snowplow/igluctl/releases/latest.
wget https://github.com/snowplow/igluctl/releases/download/0.10.2/igluctl_0.10.2.zip unzip igluctl_0.10.2.zip rm igluctl_0.10.2.zipchmod +x igluctl mv igluctl ~/binigluctl --version 0.10.2Mova o executável para algum diretório no PATH.
~/binno meu caso.
Quick Start
Repositório
Clone o repositório
git clone https://github.com/snowplow/quickstart-examplesPasta do projeto
Copie apenas o que será usado para uma nova pasta:
cp -r quickstart-examples/terraform/gcp/iglu_server/secure ~/Snowplow/iglu_server cp -r quickstart-examples/terraform/gcp/pipeline/secure ~/Snowplow/pipelineEu copiei apenas as pastas
secure, pois é o recomendado para ambientes de produção. A diferença é que o Snowplow será configurado na VPC que criamos anteriormente.
Iglu Server
Arquivo terraform.tfvars
Edite o arquivo
~/Snowplow/iglu_server/terraform.tfvars:prefix = "sp" project_id = "projeto-snowplow" region = "europe-west3" network = "snowplow-vpc" subnetwork = "snowplow-private-subnet-europe-west3" ssh_ip_allowlist = ["88.217.100.200/32", "35.235.240.0/20"] ssh_key_pairs = [ { user_name = "snowplow" public_key = "ssh-ed25519 AAAAC3NzC1lZDI…E5Gv8/gQzPr3H/9B+Nxc/GInziPJX" } ] # --- Snowplow Iglu Server iglu_db_name = "iglu" iglu_db_username = "iglu" iglu_db_password = "SENHA_DO_IGLU_BD" iglu_super_api_key = "01234567-890a-bcde-f012-34567890abcd" user_provided_id = "" telemetry_enabled = false # --- SSL Configuration (optional) ssl_information = { certificate_id = "" enabled = false } # --- Extra Labels to append to created resources (optional) labels = {}Para gerar a chave SSH:
ssh-keygen -t rsa -b 4096 -f snowplow -C "Snowplow"Para gerar um UUID aleatório: https://duckduckgo.com/?q=uuid
Comandos do Terraform
cd ~/Snowplow/iglu_server terraform init terraform plan -out plan terraform apply "plan"Anote a saída, que será o IP do Iglu Server.
A saída também é salva noterraform.tfstate:$ grep -A1 iglu_server_ip_address terraform.tfstate "iglu_server_ip_address": { "value": "34.100.100.200",Adicionar schemas no Iglu server
git clone https://github.com/snowplow/iglu-central cp -r iglu-central/schemas ~/Snowplow/ rm -rf iglu-centralcd ~/Snowplow rm -rf schemas/SCHEMAS_QUE_NAO_SERAO_USADOS igluctl static push --public schemas/ http://IP_DO_IGLU_SERVER 01234567-890a-bcde-f012-34567890abcdDeixe apenas os schemas que você irá utilizar na pasta
schemas.
O UUID no final do comando é aiglu_super_api_keyque geramos anteriormente.Inspecionar status do Iglu Server
O Iglu Server possui alguns endpoints para inspecionar seu próprio estado.
$ curl http://34.100.100.200/api/meta/health/db OK$ curl -s http://34.100.100.200/api/meta/server \ -H "apikey: 01234567-890a-bcde-f012-34567890abcd" | jq { "version": "0.8.7", "authInfo": { "vendor": "", "schema": "CREATE_VENDOR", "key": [ "CREATE", "DELETE" ] }, "database": "postgres", "schemaCount": 0, "debug": false, "patchesAllowed": true }
Pipeline
Arquivo
bigquery.terraform.tfvarsEdite o arquivo
~/Snowplow/pipeline/bigquery.terraform.tfvars:prefix = "sp" project_id = "projeto-snowplow" region = "europe-west3" network = "snowplow-vpc" subnetwork = "snowplow-private-subnet-europe-west3" ssh_ip_allowlist = ["88.217.100.200/32", "35.235.240.0/20"] ssh_key_pairs = [ { user_name = "snowplow" public_key = "ssh-ed25519 AAAAC3NzC1lZDI…E5Gv8/gQzPr3H/9B+Nxc/GInziPJX" } ] iglu_server_dns_name = "http://34.100.100.200" iglu_super_api_key = "01234567-890a-bcde-f012-34567890abcd" bigquery_db_enabled = true bigquery_loader_dead_letter_bucket_deploy = true bigquery_loader_dead_letter_bucket_name = "sp-bq-loader-dead-letter_bucket" user_provided_id = "" telemetry_enabled = false ssl_information = { certificate_id = "" enabled = false } labels = {} ########################################################################### postgres_db_enabled = true postgres_db_name = "snowplow" postgres_db_username = "snowplow" postgres_db_password = "TYPE_PG_PASSWORD_HERE" postgres_db_authorized_networks = [ { name = "julio" value = "88.217.100.200/32" } ] postgres_db_tier = "db-g1-small"Execução do Terraform
cd ~/Snowplow/pipeline terraform init terraform applyEventos de teste
Pegue o endereço do collector:
$ grep -A1 collector_ip_address terraform.tfstate "collector_ip_address": { "value": "34.111.120.123",Envie os seguintes eventos de teste:
curl 'http://34.111.120.123/com.snowplowanalytics.snowplow/tp2' \ -H 'Content-Type: application/json; charset=UTF-8' \ -H 'Cookie: _sp=305902ac-8d59-479c-ad4c-82d4a2e6bb9c' \ --data-raw \ '{ "schema": "iglu:com.snowplowanalytics.snowplow/payload_data/jsonschema/1-0-4", "data": [ { "e": "pv", "url": "/docs/open-source-quick-start/quick-start-installation-guide-on-aws/send-test-events-to-your-pipeline/", "page": "Send test events to your pipeline - Snowplow Docs", "refr": "https://docs.snowplow.io/", "tv": "js-2.17.2", "tna": "spExample", "aid": "docs-example", "p": "web", "tz": "Europe/London", "lang": "en-GB", "cs": "UTF-8", "res": "3440x1440", "cd": "24", "cookie": "1", "eid": "4e35e8c6-03c4-4c17-8202-80de5bd9d953", "dtm": "1626182778191", "cx": "eyJzY2hlbWEiOiJpZ2x1Om…YS03ZjRlNzk2OTM3ZmEifX1dfQ", "vp": "863x1299", "ds": "848x5315", "vid": "3", "sid": "87c18fc8-2055-4ec4-8ad6-fff64081c2f3", "duid": "5f06dbb0-a893-472b-b61a-7844032ab3d6", "stm": "1626182778194" }, { "e": "ue", "ue_px": "eyJzY2hlbWEiOiJpZ2x1Om…IlB1cnBsZSBTbm93cGxvdyBIb29kaWUifX19", "tv": "js-2.17.2", "tna": "spExample", "aid": "docs-example", "p": "web", "tz": "Europe/London", "lang": "en-GB", "cs": "UTF-8", "res": "3440x1440", "cd": "24", "cookie": "1", "eid": "542a79d3-a3b8-421c-99d6-543ff140a56a", "dtm": "1626182778193", "cx": "eyJzY2hlbWEiOiJpZ2x1Om…lNzk2OTM3ZmEifX1dfQ", "vp": "863x1299", "ds": "848x5315", "vid": "3", "sid": "87c18fc8-2055-4ec4-8ad6-fff64081c2f3", "duid": "5f06dbb0-a893-472b-b61a-7844032ab3d6", "refr": "https://docs.snowplow.io/", "url": "/docs/open-source-quick-start/quick-start-installation-guide-on-aws/send-test-events-to-your-pipeline/", "stm": "1626182778194" } ] }'O comando acima envia um evento que bom e um que não corresponde a nenhum schema.
Verificação no BigQuery
Entre em https://console.cloud.google.com/bigquery?project=projeto-snowplow e encontre a tabela
eventsno datasetsp_snowplow_db. Verifique se há algum dado na abaPREVIEW.Essa é a tabela de “good data”.
O pipeline para “bad data” não está incluso no Quick Start e deve ser criado manualmente.
Verificação no PostgreSQL
Pegue o IP do banco:
$ grep -A1 postgres_db_ip_address terraform.tfstate "postgres_db_ip_address": { "value": "34.89.100.100",Conecte-se usando algum programa como o DBeaver:
Host:34.89.100.100Database:snowplowPort:5432Username:snowplowPassword:TYPE_PG_PASSWORD_HERE
A tabela de “good data” é a
atomic.events.
Ela deverá estar vazia, pois a fila já foi consumida pelo BigQuery.
É necessário duplicar a fila para que o PostgreSQL também receba os eventos.Existem várias tabelas de “bad data”, uma delas é a
atomic_bad.com_snowplowanalytics_snowplow_badrows_schema_violations_1.
Próximos passos
- Configurar domínio e ativar SSL
- Criar schemas próprios
- Bad data no BigQuery
Links

Sou um engenheiro de computação brasileiro baseado na Alemanha, apaixonado por tecnologia, ciência, fotografia e línguas.
Programo há cerca de duas décadas, explorando desde aplicativos móveis e desenvolvimento web até aprendizado de máquina. Atualmente, foco em SRE de nuvem e engenharia de dados.
Sou voluntário nas comunidades de open source e Python, ajudando a organizar a PyCon DE e a PyData Berlin, mentorando e contribuindo com código e traduções.
No meu blog, compartilho dicas de Linux, guias de configuração e notas pessoais que escrevo para referência futura. Espero que outras pessoas também as considerem úteis. O conteúdo está disponível em vários idiomas.
Visite minha galeria para ver algumas das minhas fotografias.
Longe do teclado, você vai me encontrar em shows, tocando clarinete, pedalando, mergulhando ou explorando novos lugares, culturas e culinárias.
Sempre feliz em me conectar! 🙂