Snowplow

Snowplow ist ein Unternehmen mit Sitz in London, das eine Cloud-basierte „Behavioral Data Platform“ anbietet und außerdem eine Open-Source-Version. Laut der offiziellen Website ist es das drittmeist genutzte Web-Tracking-Tool, hinter Google Analytics und Facebook.
Motivation für diesen Beitrag
Die Installation und Konfiguration von Snowplow Open Source in der Google Cloud ist recht komplex – und zusätzlich ist die Dokumentation stark veraltet.
Die Dokumentation ist ebenfalls Open Source und ich habe Pull Requests eingereicht, um einige der
Fehler zu korrigieren, die ich gefunden habe.
Jedenfalls habe ich hier alles dokumentiert – zur späteren Referenz.
Ich hoffe, es hilft auch anderen.
Ich habe den gesamten Prozess zwischen Dezember 2022 und Januar 2023 auf einem MacBook Pro M1 durchgeführt. Für meinen konkreten Anwendungsfall habe ich sowohl BigQuery als auch PostgreSQL aktiviert – das kostet etwa 240 US-Dollar pro Monat.
Normalerweise nutzt man nur ein Data Warehouse. In der GCP empfehle ich BigQuery, denn:
- Es kommt gut mit großen Datenmengen zurecht.
- Einige dbt-Pakete, wie snowplow_ecommerce, sind mit PostgreSQL noch nicht kompatibel.
- Es kann – je nach Nutzung – günstiger sein (selbst mit zusätzlichem Pub/Sub):
- BigQuery wird nach Nutzung abgerechnet, nicht nach Laufzeit.
- Das erste Terabyte an Speicher ist kostenlos.
Überblick
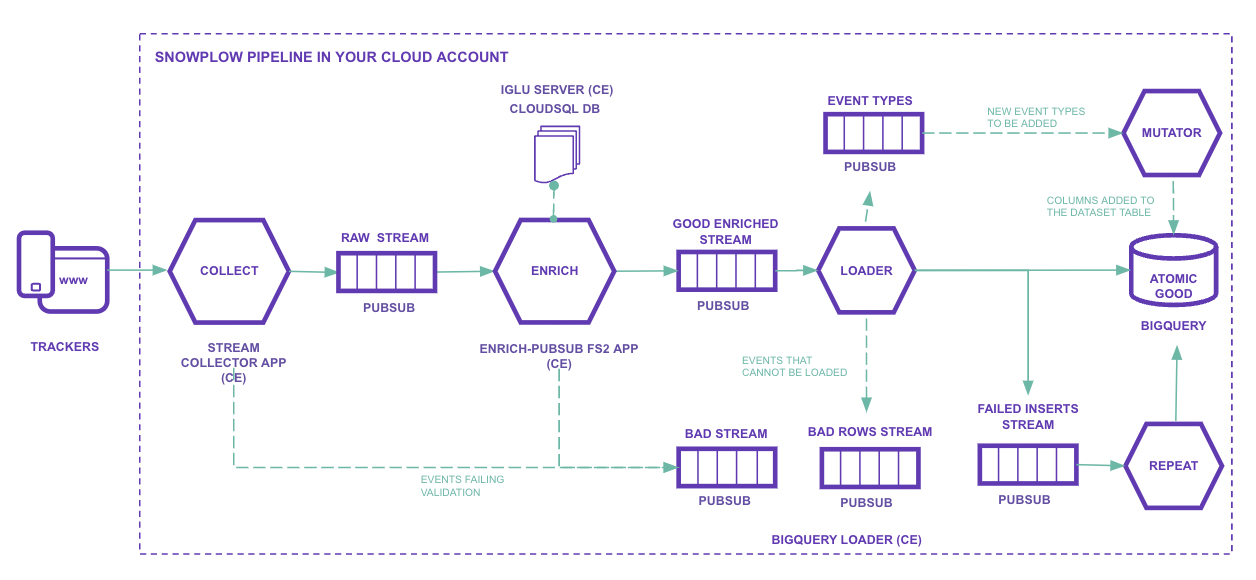
Erläuterung der Abbildung, Schritt für Schritt:
Trackers: Quellen, von denen wir Daten sammeln möchten.
Man kann alles tracken, was REST-Aufrufe machen kann: Websites, Mobile-Apps und Datenbanken.
Die SDKs helfen dabei stark.
Die Daten werden anhand eines expliziten Schemas gesendet, das du selbst definierst.Iglu Server: Compute Engine (mit Load Balancer) und Cloud SQL.
Es ist ein Repository für Schemas.
Sie werden in JSON Schema-Dateien definiert und können versioniert werden, z. B.: YouTube JSON Schema und GA Ecommerce Schema.Stream collector app: Compute Engine (mit Load Balancer).
Enthält den HTTP-Endpunkt, der rohe Events entgegennimmt, serialisiert und an Pub/Sub-Themen weiterleitet (sp-raw-topicodersp-bad-1-topic).Wenn ein Event beispielsweise zu groß ist, wird es in das Pub/Sub-Thema für „bad data“ geschickt.
Enrich PubSub: JVM-Anwendung auf Compute Engine (eine oder mehrere VMs).
In diesem Schritt werden Events aus dem „Raw Stream“ (sp-raw-topic, geschrieben vom Collector) gelesen und validiert.- Wenn das Event keinem Schema im Iglu Server entspricht, wird es in den „Bad Stream“ gesendet.
Das verhindert, dass falsche oder minderwertige Daten in die Produktion gelangen, und ermöglicht die Analyse des empfangenen Schemas, was bei der Fehlersuche hilft.
In Google Analytics würden solche Daten einfach ignoriert. - Wenn das Event einem Schema entspricht, wird es gemäß deiner Konfiguration „angereichert“.
Zum Beispiel:- Aufschlüsselung des User-Agent:
- Gerätetyp
- Betriebssystem
- Systemversion
- usw.
- IP-Adressen anonymisieren
- Personenbezogene Daten filtern (PII)
- Geolokalisierungsinformationen erweitern
- Aufschlüsselung des User-Agent:
Es gibt viele verfügbare Enrichments.
Nach der „Anreicherung“ wird das Event an das Thema „Good Enriched“ (
sp-enriched-topic) gesendet.- Wenn das Event keinem Schema im Iglu Server entspricht, wird es in den „Bad Stream“ gesendet.
Loader: lädt in Tabellen.
Wenn der Loader Zeilen nicht in BigQuery einfügen kann, werden sie an einen „failed inserts“-Stream gesendet und das Einfügen wird erneut versucht.Mutator: Wird verwendet, wenn ein Schema geändert oder erweitert werden muss. Alle Events gehen in eine einzige große Tabelle. Eine Schemaänderung kann große Auswirkungen haben.
Terraform
Anstatt jeden Google-Cloud-Ressourcen manuell über die Weboberfläche oder die Kommandozeile zu erstellen und zu konfigurieren, definierst du mit Terraform die Infrastruktur deklarativ als Code in einer eigenen Sprache, die auf HCL (HashiCorp Configuration Language) basiert.
Wie jeder Code können auch Terraform-Dateien versioniert werden, was Änderungen und Rollbacks vereinfacht.
Es gibt einen Quick Start, der das Deployment mit Terraform durchführt. Leider decken die aktuellen Module nicht alle Setups ab und einige sind ziemlich veraltet. Ich verwende sie trotzdem als Basis, denn Terraform reduziert das Fehlerrisiko und erleichtert die Wartung der Infrastruktur.
Voraussetzungen
Projekt erstellen
Erstelle ein Projekt in der Google Cloud und aktiviere Billing.
Ich verwende in diesem Beitrag den Namenprojeto-snowplow.Terraform installieren
brew install terraformGoogle Cloud CLI installieren
brew install google-cloud-sdk$ gcloud version Google Cloud SDK 412.0.0 bq 2.0.83 core 2022.12.09 gcloud-crc32c 1.0.0 gsutil 5.17gcloud auth loginFüge in
~/.zshrchinzu:source "$(brew --prefix)/Caskroom/google-cloud-sdk/latest/google-cloud-sdk/path.zsh.incDieser Befehl fügt das Verzeichnis
/opt/homebrew/Caskroom/google-cloud-sdk/latest/google-cloud-sdk/bindeinem PATH hinzu.Service Account
Lege einen Service Account namens
spsetupanMenu » IAM and admin » Service accounts » Create Service AccountErzeuge einen Schlüssel
KEYS » Add Key » Key type: JSON
Speichere die Datei als~/Snowplow/key.json.Setze die Umgebungsvariable auf den Dateipfad
export GOOGLE_APPLICATION_CREDENTIALS="/Users/julio/Snowplow/key.json"
APIs aktivieren
Rufe die folgenden Links auf und aktiviere die APIs:
VPC und Subnetze
Die „sichere“ Snowplow-Konfiguration erfordert eine VPC. Du kannst sie über die Weboberfläche, die Kommandozeile oder per Terraform erstellen.
Über die Kommandozeile:
gcloud compute networks create \ vpc-snowplow \ --project=projeto-snowplow \ --description=Snowplow\ VPC \ --subnet-mode=custom \ --mtu=1460 \ --bgp-routing-mode=regionalgcloud compute networks subnets create \ vpc-snowplow-europe-west3 \ --project=projeto-snowplow \ --range=10.0.0.0/24 \ --stack-type=IPV4_ONLY \ --network=vpc-snowplow \ --region=europe-west3 \ --enable-private-ip-google-accessMit Terraform:
# VPC # https://www.terraform.io/docs/providers/google/r/compute_network.html # Keep the default route (0.0.0.0/0) to allow internet access resource "google_compute_network" "snowplow_vpc" { name = "snowplow-vpc" routing_mode = "REGIONAL" auto_create_subnetworks = false delete_default_routes_on_create = false }# Private Subnet # https://www.terraform.io/docs/providers/google/r/compute_subnetwork.html resource "google_compute_subnetwork" "snowplow_private_subnet" { name = "snowplow-private-subnet-europe-west3" ip_cidr_range = "10.0.0.0/24" region = var.region network = google_compute_network.snowplow_vpc.id private_ip_google_access = true }
Cloud Router
Über die Kommandozeile:
gcloud compute routers create router-snowplow \ --project=projeto-snowplow \ --description=To\ allow\ access\ to\ the\ internet \ --region=europe-west3 \ --network=vpc-snowplow \ --set-advertisement-mode=customMit Terraform:
# Cloud Router # https://www.terraform.io/docs/providers/google/r/compute_router.html resource "google_compute_router" "snowplow_router" { name = "snowplow-router" region = var.region network = google_compute_network.snowplow_vpc.id bgp { asn = 64514 advertise_mode = "CUSTOM" } }
Cloud NAT
Erstelle ein NAT-Gateway. Darüber erhalten die VMs Zugang zum Internet.
Mit Terraform:
# NAT Gateway # https://www.terraform.io/docs/providers/google/r/compute_router_nat.html resource "google_compute_router_nat" "snowplow_nat" { name = "snowplow-nat" router = google_compute_router.snowplow_router.name region = google_compute_router.snowplow_router.region nat_ip_allocate_option = "AUTO_ONLY" source_subnetwork_ip_ranges_to_nat = "LIST_OF_SUBNETWORKS" subnetwork { name = google_compute_subnetwork.snowplow_private_subnet.id source_ip_ranges_to_nat = ["ALL_IP_RANGES"] } log_config { enable = true filter = "ERRORS_ONLY" } }
Java
brew install java brew install openjdksudo ln -sfn \ $(brew --prefix)/opt/openjdk@11/libexec/openjdk.jdk \ /Library/Java/JavaVirtualMachines/openjdk-11.jdkIgluctl
Kopiere den Link zur neuesten Version von https://github.com/snowplow/igluctl/releases/latest.
wget https://github.com/snowplow/igluctl/releases/download/0.10.2/igluctl_0.10.2.zip unzip igluctl_0.10.2.zip rm igluctl_0.10.2.zipchmod +x igluctl mv igluctl ~/binigluctl --version 0.10.2Verschiebe die ausführbare Datei in ein Verzeichnis, das im PATH liegt – bei mir
~/bin.
Quick Start
Repository
Klone das Repository:
git clone https://github.com/snowplow/quickstart-examplesProjektordner
Kopiere nur die Teile, die du verwenden wirst, in einen neuen Ordner:
cp -r quickstart-examples/terraform/gcp/iglu_server/secure ~/Snowplow/iglu_server cp -r quickstart-examples/terraform/gcp/pipeline/secure ~/Snowplow/pipelineIch habe nur die Ordner
securekopiert, da diese für Produktionsumgebungen empfohlen werden. Der Unterschied ist, dass Snowplow in der VPC konfiguriert wird, die wir zuvor erstellt haben.
Iglu Server
Datei
terraform.tfvarsBearbeite
~/Snowplow/iglu_server/terraform.tfvars:prefix = "sp" project_id = "projeto-snowplow" region = "europe-west3" network = "snowplow-vpc" subnetwork = "snowplow-private-subnet-europe-west3" ssh_ip_allowlist = ["88.217.100.200/32", "35.235.240.0/20"] ssh_key_pairs = [ { user_name = "snowplow" public_key = "ssh-ed25519 AAAAC3NzC1lZDI…E5Gv8/gQzPr3H/9B+Nxc/GInziPJX" } ] # --- Snowplow Iglu Server iglu_db_name = "iglu" iglu_db_username = "iglu" iglu_db_password = "SENHA_DO_IGLU_BD" iglu_super_api_key = "01234567-890a-bcde-f012-34567890abcd" user_provided_id = "" telemetry_enabled = false # --- SSL Configuration (optional) ssl_information = { certificate_id = "" enabled = false } # --- Extra Labels to append to created resources (optional) labels = {}SSH-Schlüssel erzeugen:
ssh-keygen -t rsa -b 4096 -f snowplow -C "Snowplow"Zufällige UUID generieren: https://duckduckgo.com/?q=uuid
Terraform-Befehle
cd ~/Snowplow/iglu_server terraform init terraform plan -out plan terraform apply "plan"Notiere die Ausgabe – das ist die IP des Iglu Servers.
Die Ausgabe wird auch interraform.tfstategespeichert:$ grep -A1 iglu_server_ip_address terraform.tfstate "iglu_server_ip_address": { "value": "34.100.100.200",Schemas zum Iglu Server hinzufügen
git clone https://github.com/snowplow/iglu-central cp -r iglu-central/schemas ~/Snowplow/ rm -rf iglu-centralcd ~/Snowplow rm -rf schemas/SCHEMAS_QUE_NAO_SERAO_USADOS igluctl static push --public schemas/ http://IP_DO_IGLU_SERVER 01234567-890a-bcde-f012-34567890abcdLasse nur die Schemas in
schemas, die du verwenden wirst.
Die UUID am Ende des Befehls ist deriglu_super_api_key, den wir zuvor generiert haben.Status des Iglu Servers prüfen
Der Iglu Server bietet einige Endpoints, um seinen eigenen Status zu inspizieren.
$ curl http://34.100.100.200/api/meta/health/db OK$ curl -s http://34.100.100.200/api/meta/server \ -H "apikey: 01234567-890a-bcde-f012-34567890abcd" | jq { "version": "0.8.7", "authInfo": { "vendor": "", "schema": "CREATE_VENDOR", "key": [ "CREATE", "DELETE" ] }, "database": "postgres", "schemaCount": 0, "debug": false, "patchesAllowed": true }
Pipeline
Datei
bigquery.terraform.tfvarsBearbeite
~/Snowplow/pipeline/bigquery.terraform.tfvars:prefix = "sp" project_id = "projeto-snowplow" region = "europe-west3" network = "snowplow-vpc" subnetwork = "snowplow-private-subnet-europe-west3" ssh_ip_allowlist = ["88.217.100.200/32", "35.235.240.0/20"] ssh_key_pairs = [ { user_name = "snowplow" public_key = "ssh-ed25519 AAAAC3NzC1lZDI…E5Gv8/gQzPr3H/9B+Nxc/GInziPJX" } ] iglu_server_dns_name = "http://34.100.100.200" iglu_super_api_key = "01234567-890a-bcde-f012-34567890abcd" bigquery_db_enabled = true bigquery_loader_dead_letter_bucket_deploy = true bigquery_loader_dead_letter_bucket_name = "sp-bq-loader-dead-letter_bucket" user_provided_id = "" telemetry_enabled = false ssl_information = { certificate_id = "" enabled = false } labels = {} ########################################################################### postgres_db_enabled = true postgres_db_name = "snowplow" postgres_db_username = "snowplow" postgres_db_password = "TYPE_PG_PASSWORD_HERE" postgres_db_authorized_networks = [ { name = "julio" value = "88.217.100.200/32" } ] postgres_db_tier = "db-g1-small"Terraform ausführen
cd ~/Snowplow/pipeline terraform init terraform applyTest-Events
Ermittle die Collector-Adresse:
$ grep -A1 collector_ip_address terraform.tfstate "collector_ip_address": { "value": "34.111.120.123",Sende die folgenden Test-Events:
curl 'http://34.111.120.123/com.snowplowanalytics.snowplow/tp2' \ -H 'Content-Type: application/json; charset=UTF-8' \ -H 'Cookie: _sp=305902ac-8d59-479c-ad4c-82d4a2e6bb9c' \ --data-raw \ '{ "schema": "iglu:com.snowplowanalytics.snowplow/payload_data/jsonschema/1-0-4", "data": [ { "e": "pv", "url": "/docs/open-source-quick-start/quick-start-installation-guide-on-aws/send-test-events-to-your-pipeline/", "page": "Send test events to your pipeline - Snowplow Docs", "refr": "https://docs.snowplow.io/", "tv": "js-2.17.2", "tna": "spExample", "aid": "docs-example", "p": "web", "tz": "Europe/London", "lang": "en-GB", "cs": "UTF-8", "res": "3440x1440", "cd": "24", "cookie": "1", "eid": "4e35e8c6-03c4-4c17-8202-80de5bd9d953", "dtm": "1626182778191", "cx": "eyJzY2hlbWEiOiJpZ2x1Om…YS03ZjRlNzk2OTM3ZmEifX1dfQ", "vp": "863x1299", "ds": "848x5315", "vid": "3", "sid": "87c18fc8-2055-4ec4-8ad6-fff64081c2f3", "duid": "5f06dbb0-a893-472b-b61a-7844032ab3d6", "stm": "1626182778194" }, { "e": "ue", "ue_px": "eyJzY2hlbWEiOiJpZ2x1Om…IlB1cnBsZSBTbm93cGxvdyBIb29kaWUifX19", "tv": "js-2.17.2", "tna": "spExample", "aid": "docs-example", "p": "web", "tz": "Europe/London", "lang": "en-GB", "cs": "UTF-8", "res": "3440x1440", "cd": "24", "cookie": "1", "eid": "542a79d3-a3b8-421c-99d6-543ff140a56a", "dtm": "1626182778193", "cx": "eyJzY2hlbWEiOiJpZ2x1Om…lNzk2OTM3ZmEifX1dfQ", "vp": "863x1299", "ds": "848x5315", "vid": "3", "sid": "87c18fc8-2055-4ec4-8ad6-fff64081c2f3", "duid": "5f06dbb0-a893-472b-b61a-7844032ab3d6", "refr": "https://docs.snowplow.io/", "url": "/docs/open-source-quick-start/quick-start-installation-guide-on-aws/send-test-events-to-your-pipeline/", "stm": "1626182778194" } ] }'Der obige Befehl sendet ein gültiges Event und eines, das keinem Schema entspricht.
Überprüfung in BigQuery
Gehe zu https://console.cloud.google.com/bigquery?project=projeto-snowplow und suche die Tabelle
eventsim Datasetsp_snowplow_db. Prüfe unterPREVIEW, ob Daten vorhanden sind.Das ist die Tabelle mit den „good data“.
Die Pipeline für „bad data“ ist im Quick Start nicht enthalten und muss manuell erstellt werden.
Überprüfung in PostgreSQL
Ermittle die IP der Datenbank:
$ grep -A1 postgres_db_ip_address terraform.tfstate "postgres_db_ip_address": { "value": "34.89.100.100",Verbinde dich mit einem Tool wie DBeaver:
- Host:
34.89.100.100 - Database:
snowplow - Port:
5432 - Username:
snowplow - Password:
TYPE_PG_PASSWORD_HERE
Die „good data“-Tabelle ist
atomic.events.
Sie dürfte leer sein, weil die Queue bereits von BigQuery konsumiert wurde.
Um PostgreSQL ebenfalls mit Events zu versorgen, muss der Stream dupliziert werden.Es gibt mehrere „bad data“-Tabellen, z. B. die
atomic_bad.com_snowplowanalytics_snowplow_badrows_schema_violations_1.- Host:
Nächste Schritte
- Domain konfigurieren und SSL aktivieren
- Eigene Schemas erstellen
- Bad Data in BigQuery ablegen
Links

Ich bin ein brasilianischer Computeringenieur mit Wohnsitz in Deutschland und begeistere mich für Technik, Wissenschaft, Fotografie und Sprachen.
Ich programmiere seit etwa zwei Jahrzehnten und habe dabei alles von mobilen Apps und Webentwicklung bis hin zu Machine Learning erkundet. Derzeit fokussiere ich mich auf Cloud‑SRE und Data Engineering.
Ich engagiere mich ehrenamtlich in den Open‑Source- und Python‑Communities, helfe bei der Organisation der PyCon DE und PyData Berlin, betreue als Mentor und trage mit Code und Übersetzungen bei.
In meinem Blog teile ich Linux‑Tipps, Einrichtungsanleitungen und persönliche Notizen, die ich als spätere Referenz geschrieben habe. Ich hoffe, dass sie auch anderen nützlich sind. Die Inhalte sind in mehreren Sprachen verfügbar.
Schau dir meine Galerie an, um einige meiner Fotografien zu sehen.
Abseits der Tastatur findest du mich auf Konzerten, beim Klarinettenspiel, Radfahren, Tauchen oder beim Erkunden neuer Orte, Kulturen und Küchen.
Ich freue mich immer über den Austausch! 🙂